What You Get
We build autonomous AI agents that monitor, heal, and optimise your production systems around the clock. Your engineers ship features. Our agents handle the rest.
Sound Familiar?
These aren't hypotheticals. They're real conversations we have with CTOs every week.
60% of Engineering Time Lost to Ops
Your senior engineers are drowning in PagerDuty alerts, manual deployments, and infrastructure firefighting. Every hour spent on-call is an hour not spent shipping the features your customers are waiting for.
AI Prototypes That Never Reach Production
Your team built a promising AI demo in a week. Six months later, it's still not in production. The gap between prototype and production-grade AI agent is where most companies stall.
30 Tools, Zero Integration
Slack, Jira, databases, CI/CD, monitoring. Your stack is fragmented. Without a unified context layer, your AI agents can't access the data they need to actually be useful.
We've fixed all of these. Here's how.
What We Do
Four capabilities. One outcome: autonomous operations that free your engineering team to build what matters.


They Brought the Challenge. We Delivered.
Real engagements. Measurable outcomes. Every metric below is from a production deployment.
Series B SaaS Company
The Problem
Their fraud detection model worked in staging. Six months later, still not in production. The ML team was blocked by infrastructure, and the platform team was drowning in on-call rotations.
What We Did
We deployed a multi-agent AI pipeline with a working MVP in 1 week: containerised model serving, automated retraining with drift detection, A/B testing, and Kubernetes auto-scaling, all governed by agentic SRE monitoring.
Results
FinTech, $40M ARR
The Problem
AWS bill hit $65K/month. The CFO wanted a breakdown by team and project. The CTO had no answer, just 'that's what the models cost.' Zero visibility, zero accountability.
What We Did
Our AI-powered FinOps audit identified $39K in waste: oversized GPU instances, idle dev environments, and mismatched reservations. Deployed agentic cost monitoring that catches anomalies in real time.
Results
Enterprise Data Platform
The Problem
Every deployment required 2 weeks, 3 teams, and a change advisory board. Friday deploys meant weekend work. Engineer attrition hit 30%. Something had to change.
What We Did
We built an agentic SRE pipeline: GitOps with canary deployments, instant automated rollbacks, and Slack-based AI monitoring. Engineers push code. Our agents handle everything else.
Results
Your challenge could be next. Here's how we get there.
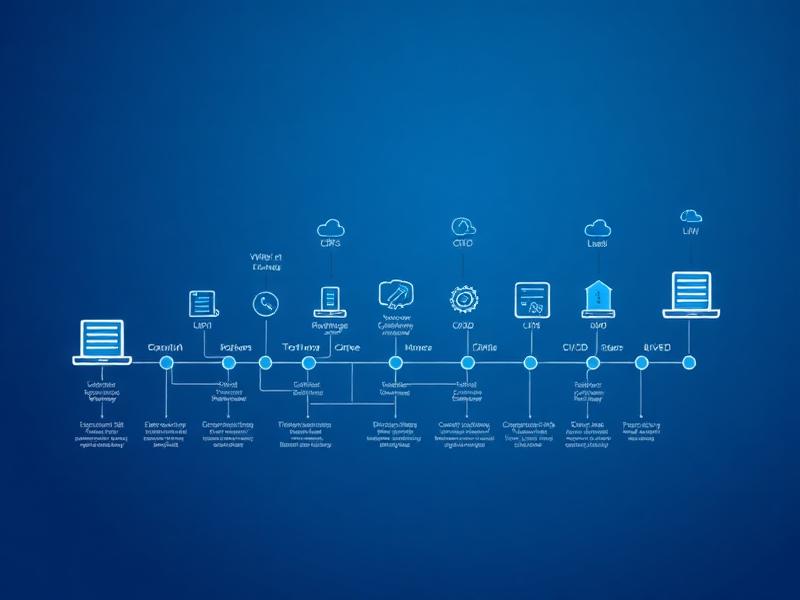
How We Work
From your first conversation to autonomous AI operations. We stay as long as you need us.
Diagnose
Day 1
We audit your current systems, map your workflows, and identify the highest-ROI automation targets. No fluff, just a clear action plan.
Architect
Days 2–3
We design the agent system: orchestration, integrations, data flows, and deployment strategy. You review and approve before a line of code is written.
Ship
Days 4–5
Working MVP delivered. AI agents connected to your real systems, deployed to your infrastructure. Not a demo. A live system you can test immediately.
Operate
Ongoing
Our agents run 24/7. We monitor performance, handle drift, and continuously improve. You get monthly reports with ROI metrics.
Diagnose
Day 1We audit your current systems, map your workflows, and identify the highest-ROI automation targets. No fluff, just a clear action plan.
Architect
Days 2–3We design the agent system: orchestration, integrations, data flows, and deployment strategy. You review and approve before a line of code is written.
Ship
Days 4–5Working MVP delivered. AI agents connected to your real systems, deployed to your infrastructure. Not a demo. A live system you can test immediately.
Operate
OngoingOur agents run 24/7. We monitor performance, handle drift, and continuously improve. You get monthly reports with ROI metrics.
What You Get
Zero 3am Pages
AI agents detect, triage, and resolve incidents before your team wakes up
Self-Healing Infrastructure
Automated remediation for common failures. Rollbacks, restarts, and scaling, all handled
Slack-Native Observability
Real-time production status, incident updates, and cost alerts delivered in Slack
1-Week MVP Guarantee
From signed contract to a working prototype in 5 business days. AI agents, infra, integrations included
Your Team, Extended
We embed with your engineering org. Shared Slack channels, weekly syncs, full transparency
Measurable ROI
Monthly reports with cost savings, incident reduction, and deployment velocity metrics